
Multimodal Models in AI
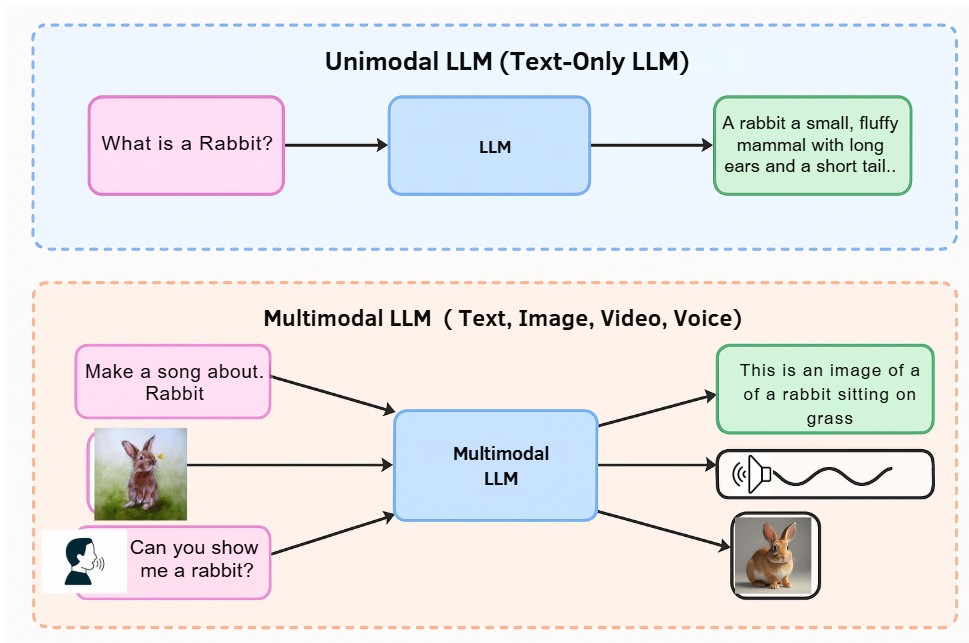
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have transformed how we interact with machines. However, a significant advancement has emerged in recent years: multimodal learning. This post explores what multimodal LLMs are and how they differ from their traditional text-only counterparts.
What Are Traditional LLMs?
Traditional or unimodal LLMs, as illustrated in the top portion of our diagram, operate exclusively in the text domain. These models can process and generate text based on written prompts. For example, when asked to “Describe dog,” a traditional LLM can produce text explaining what a dog is, its characteristics, and behaviors.
These text-only models have excelled at tasks like summarization, creative writing, code generation, and answering questions – but they’re fundamentally limited to a single modality: text.
Enter Multimodal LLMs: Bridging Different Types of Data
Multimodal LLMs, shown in the bottom portion of our diagram, represent a significant evolution. These advanced systems can process and generate content across multiple modalities, including:
- Text: Written language input and output
- Images: Visual data recognition and generation
- Audio: Sound recognition and generation
Using our example diagram, a multimodal LLM can:
- Accept an image of a dog and describe it accurately (“This is an image of a dog sitting on grass”)
- Generate an image based on a text prompt (“Give me the image of dog”)
- Create audio content like a song based on a text request (“Make a song about dog”)
Key Differences Between Unimodal and Multimodal LLMs
- Input Versatility: While traditional LLMs accept only text inputs, multimodal models can process diverse data types simultaneously.
- Output Capabilities: Multimodal LLMs can respond not just with text but also with generated images, audio, or other modalities.
- Contextual Understanding: By processing multiple modalities together, these models develop richer contextual understanding – they can “see” an image while reading text about it, creating more nuanced comprehension.
- Real-World Applications: Multimodal LLMs can tackle complex tasks that require understanding relationships between different types of data, such as visual question answering or creating content that spans multiple media types.
Why Multimodal LLMs Matter
The advancement from unimodal to multimodal learning mirrors human cognition. We don’t experience the world through just one sense – we integrate visual information, sounds, text, and more to form comprehensive understanding.
Multimodal LLMs bring AI closer to this human-like perception by breaking free from the constraints of text-only processing. This enables more natural human-computer interaction and opens possibilities for applications in fields where multiple types of data must be processed simultaneously – from healthcare diagnostics to creative content production.
Looking Forward
As multimodal AI continues to develop, we can expect increasingly sophisticated applications that seamlessly blend different types of data. The boundary between different modalities will become less distinct, leading to AI systems that interact with the world in ways that more closely resemble human cognition. The evolution from text-only LLMs to multimodal systems represents not just a technical advancement but a fundamental shift in how AI perceives and interacts with our multifaceted world.
Building Multimodal Systems from Specialized Unimodal Components”
Some unimodal models are so good and precise that it would not make sense to make them bigger or more complex by adding multimodal capabilities. So, instead you can create an interaction process where you send the question in text and if an image is requested or in the input, it can send it to a specialized image model to create or interpret.
Several special-purpose unimodal models can definitely interact to create a multimodal application. This is actually a common approach in building multimodal systems. Rather than having a single monolithic model that handles all modalities, many multimodal applications use an architecture where specialized unimodal models work together:
- Component-based architecture: Each modality (text, image, audio, etc.) is processed by a specialized model designed specifically for that data type. For example:
- Text processing by a text-only LLM
- Image recognition by a vision model
- Audio processing by a speech recognition model
- Integration layer: The outputs from these specialized models are then combined through an integration layer that aligns and fuses the information from different modalities.
- Orchestration: A central system coordinates how these models communicate and how their outputs are combined to produce the final result.
This approach has several advantages:
- Each specialized model can be optimized for its specific modality
- Models can be updated or replaced independently
- The system can be more resource-efficient by activating only the necessary components
- Development can be more modular and easier to debug
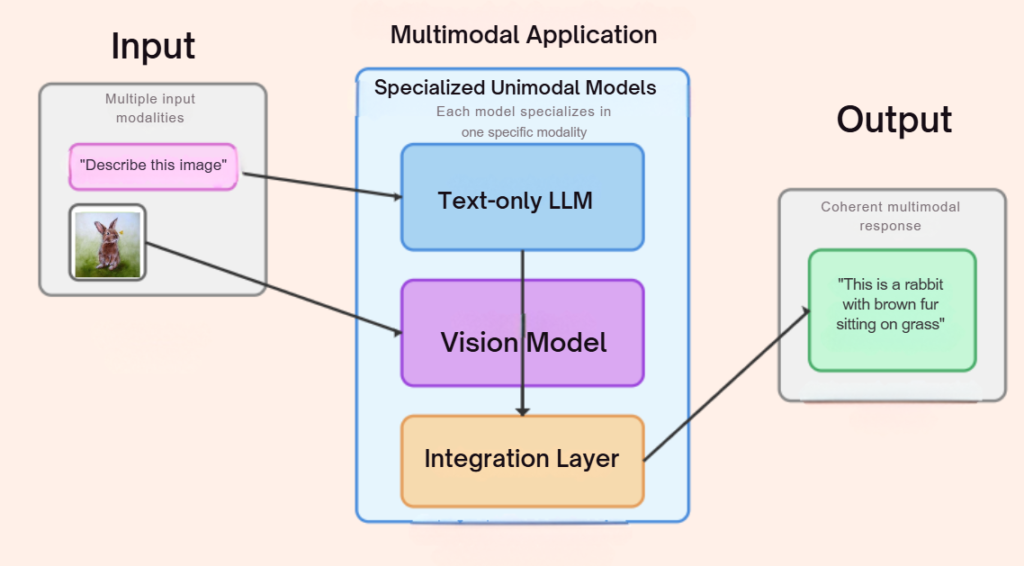
For example, a virtual assistant might use:
- A vision model to process camera input
- A speech recognition model for audio input
- A text-based LLM to generate responses
- A text-to-speech model to vocalize those responses
While true end-to-end multimodal models (trained to handle multiple modalities simultaneously) are becoming more common, many production systems still use these ensemble approaches with specialized components working together.
The key distinction is that a true multimodal LLM learns joint representations across modalities during training, while a multimodal application built from unimodal components combines the separate representations after they’ve been independently processed.



")