
Understanding AI Tokens: The Building Blocks of AI Applications

Part of: AI Learning Series Here
Quick Links: Resources for Learning AI | Keep up with AI | List of AI Tools | Local AI | AI Agents | Future of Work
Subscribe to JorgeTechBits newsletter

In the world of Artificial Intelligence (AI) and Machine Learning (ML), tokens are the fundamental currency of communication. Whether you are using a chatbot, generating an image, or analyzing a complex document, every interaction is governed by the “token economy.”
Understanding tokens is the key to mastering AI productivity, managing your budget, and understanding why models occasionally “forget” what you’ve said.
What Are AI Tokens?
In the context of AI, tokens are the basic units of language that a model processes. Think of them as the “atoms” of a sentence. Because computers cannot understand raw text the way humans do, they must convert text into numerical representations. Tokens serve as the bridge between human language and computer math.
Tokens are small pieces of text that language models process. They aren’t exactly words – they’re smaller chunks that might be:
- Complete words (like “hello” or “computer”)
- Parts of words (like “un” and “likely” from “unlikely”)
- Punctuation marks (like “.” or “?”)
- Special characters
Imagine language as a puzzle. While traditional computers might see each word as a single puzzle piece, AI models break language down into smaller, more manageable pieces:
- Complete Words: Common words like “the,” “computer,” or “hello.”
- Subwords: Parts of words like “un-” and “happy” (from the word “unhappy”).
- Punctuation & Characters: Symbols like “!”, “?”, or individual letters.
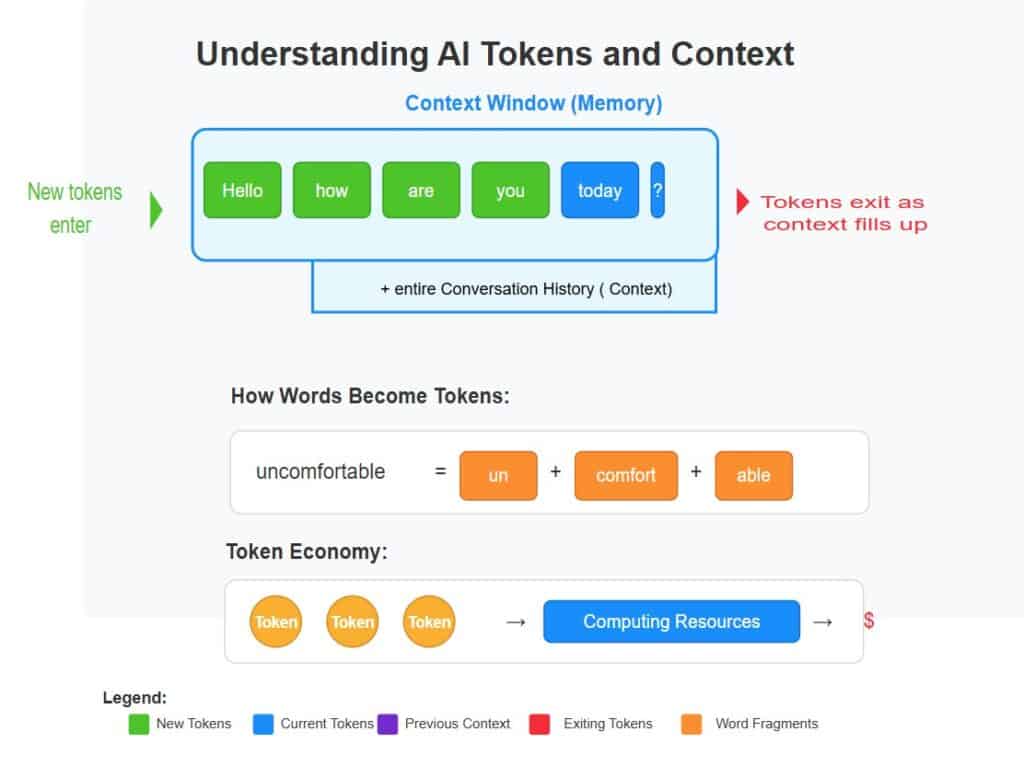
or example, the word “uncomfortable” is often processed as three separate tokens: un + comfort + able. This approach, called Subword-Level Tokenization, allows the AI to handle complex words and recognize that “walking,” “walked,” and “walker” all share the root “walk.”
The 75% Rule: As a general rule of thumb, 1,000 tokens is roughly equal to 750 words. This is about the length of a single-spaced page of text.
For instance, when you say “uncomfortable,” an AI doesn’t see just one word. It might see “un” + “comfort” + “able” – three separate tokens that together form the complete meaning. Common words like “the” or “and” might be single tokens, while specialized terms like “photosynthesis” might be broken into multiple pieces.
This tokenization is similar to how children learn to read – first understanding letters, then syllables, then complete words. AI follows a similar path, building understanding from these fundamental units.
The Three Pillars of Token Metrics
When evaluating an AI model or building an application, you must balance three critical metrics: speed, memory, and cost.
1. Tokens Per Second (TPS) – The Speedometer
TPS measures inference speed, or how quickly the AI generates output.
- High TPS: The AI feels “snappy” and types faster than a human can read.
- Low TPS: The AI feels sluggish, which can hurt user experience in real-time applications like customer support.
2. The Context Window – The Memory
Every AI has a limit on how many tokens it can “remember” at one time. This is its Context Window. Think of it as a moving spotlight on a long scroll of text.
As new tokens enter from one end, old tokens eventually fall out the other end. If you ask a chatbot, “What about the red one?” it only knows you’re referring to the car mentioned earlier because that car is still within its “spotlight” of memory. Premium models like Claude 3.5 or Gemini 1.5 Pro have massive context windows (up to 2 million tokens), allowing them to “read” entire books or codebases in one go.
3. Cost per Million Tokens – The Economy
The economics of AI applications flow directly from token usage. It works like a water utility: just as you pay for each gallon of water flowing through your pipes, companies pay for each token flowing through their systems.
- Input vs. Output: Most providers charge a cheaper rate for the tokens you send (input) and a higher rate for the tokens the AI generates (output).
- Pricing Tiers: A basic model might charge $0.25 per million tokens, while an advanced, high-reasoning model might charge $15.00 per million.
- The Price Drop: Driven by open-source competition (like Meta’s Llama models), the price of tokens is falling rapidly. When providers don’t have to recoup massive development costs, they compete directly on price.
Summary Checklist
| Metric | Focus | Real-World Analogy |
| TPS | Speed | The flow rate of your faucet. |
| Context Window | Memory | The size of your water tank. |
| Price per 1M | Economy | Your monthly utility bill. |
How Tokens Impact AI Application Costs
The economics of AI applications flow directly from token usage. Consider a water utility analogy: just as you pay for each gallon of water flowing through your pipes, companies pay for each token flowing through their AI systems.
When you interact with ChatGPT or Claude, you’re essentially turning on a digital faucet. Every question you ask (input tokens) and every answer you receive (output tokens) adds to the bill. A simple question might cost pennies, but a lengthy conversation analyzing a 30-page document could cost significantly more.
Large language models are like luxury water treatment plants – they provide higher quality, but at a premium price per unit. A basic model might charge $1 per million tokens, while an advanced model might charge $30 per million tokens.
The context window – how much information the AI can consider at once – is like the size of your water tank. Larger tanks (context windows) cost more but allow for more comprehensive processing. When someone asks Claude to analyze an entire book, they’re essentially requesting a very large water tank.
NOTE: The price of AI tokens and computing is expected to continue decreasing over time. They are already falling rapidly, driven by several factors including the release of open-source models like Llama 3.1. When API providers don’t have to recoup the cost of developing a model, they can compete directly on price, leading to ongoing price reductions.
Optimizing Token Usage for Efficiency
Efficient token usage is similar to water conservation. Just as you wouldn’t leave the tap running unnecessarily, smart AI developers design systems to accomplish goals with minimal token waste.
Consider these two prompts:
- “Tell me about artificial intelligence in detail with many examples” (~15 tokens)
- “AI overview” (~3 tokens)
Both might yield useful information, but when scaled to millions of interactions, the first prompt costs five times as much. Smart system design uses “low-flow” prompts—getting the same high-quality results with fewer tokens.
Consider how differently these prompts would be tokenized: “Tell me about artificial intelligence in detail with many examples” versus “AI overview”
The first might use 12-15 tokens, while the second uses just 2-3 tokens. Both might yield useful information, but at dramatically different costs when scaled to millions of interactions. Smart AI developers design systems that accomplish goals with minimal token usage – like engineers designing low-flow fixtures that maintain performance while reducing consumption.
The Power of Context: How AI Remembers Your Conversation
Context in AI is like short-term memory in humans. When you’re having a conversation with a friend, you naturally remember what was said a few minutes ago. Similarly, AI models maintain a “memory” of your interaction through what we call the context window.
Think of the context window as a moving spotlight on a long scroll of text. As new tokens enter from one end, old tokens eventually fall out the other end. This spotlight can only illuminate a certain number of tokens at once – that’s the context size.
When you ask, “What about the red one?” a human friend knows you’re referring to something previously mentioned because they remember the context. AI works the same way, but its memory is strictly limited by token count.
The context window is like a train with a fixed number of cars. New information (tokens) boards at the front while old information eventually gets dropped off at the back once the train is full. Premium AI models have longer trains – they can remember more of your conversation, but at a higher cost per mile traveled.
How Tokens and Context Flow Through AI Systems
The context window – how much information the AI can consider at once – is like the size of your water tank. Larger tanks (context windows) cost more but allow for more comprehensive processing. When someone asks Claude to analyze an entire book, they’re essentially requesting a very large water tank.
The journey of tokens through an AI system resembles water flowing through a series of connected pools. Your input text is first broken down into tokens – like raindrops falling into the first pool. These tokens then flow into the vast reservoir of the AI’s context window.
With each interaction, new tokens pour in while the oldest ones spill out once the reservoir reaches capacity. A small chatbot might have a shallow pool holding only 4,000 tokens (roughly 3,000 words), while advanced models like Claude can maintain deeper pools of 100,000+ tokens.
When you upload a large document, you’re essentially dumping a large volume of water into this system all at once. The system must process each token, which takes computational resources – like pumps and filters in our water analogy. Each token processed adds to your bill.
A concrete example: Uploading a 20-page research paper might consume 30,000 tokens. If you then have a back-and-forth conversation about this paper that adds another 10,000 tokens, you’re using 40,000 tokens total. At a rate of $10 per million tokens, this would cost about 40 cents – small for one interaction, but significant when scaled to thousands or millions of users.
Tokens are just the beginning, understanding AI Inference
Tokens are the architectural foundation of how AI “thinks” and communicates. By understanding the balance between processing speeds, memory limits, and the evolving economics of the token market, you can better navigate and optimize your own AI journey.
We explore AI inference on this blog post– the moment when an AI model actually generates a response. Think of training as building a factory, while inference is running that factory to produce goods. We examine how inference resembles a production line where raw materials (your prompts) are transformed into finished products (AI responses), and how different production schedules (batch processing vs. real-time) affect both cost and delivery speed.
As always, hope this helps!
Have questions, ideas to share, or just want to connect? I’d love to hear from you! Check out my About Page to learn more about me or connect with me.

")



